
LiftQuant: Ancho de bits continuo en LLM mediante elevación dimensional
Descubre LiftQuant: cuantización continua de LLM que permite comprimir modelos de 70B a tan solo 2.4 bits, ajustándose perfectamente a tu memoria GPU.
Descubre LiftQuant: cuantización continua de LLM que permite comprimir modelos de 70B a tan solo 2.4 bits, ajustándose perfectamente a tu memoria GPU.

Descubre cómo un nuevo enfoque de NAS optimiza arquitectura y cuantización en LLM, logrando hasta 1.4x más velocidad y 6% más precisión en tareas de razonamiento. ¡Mejora tus despliegues en edge!

Descubre YAQA: algoritmo de redondeo adaptativo que reduce el error de cuantización un 30% frente a GPTQ. Cotas de error garantizadas sin coste de inferencia.
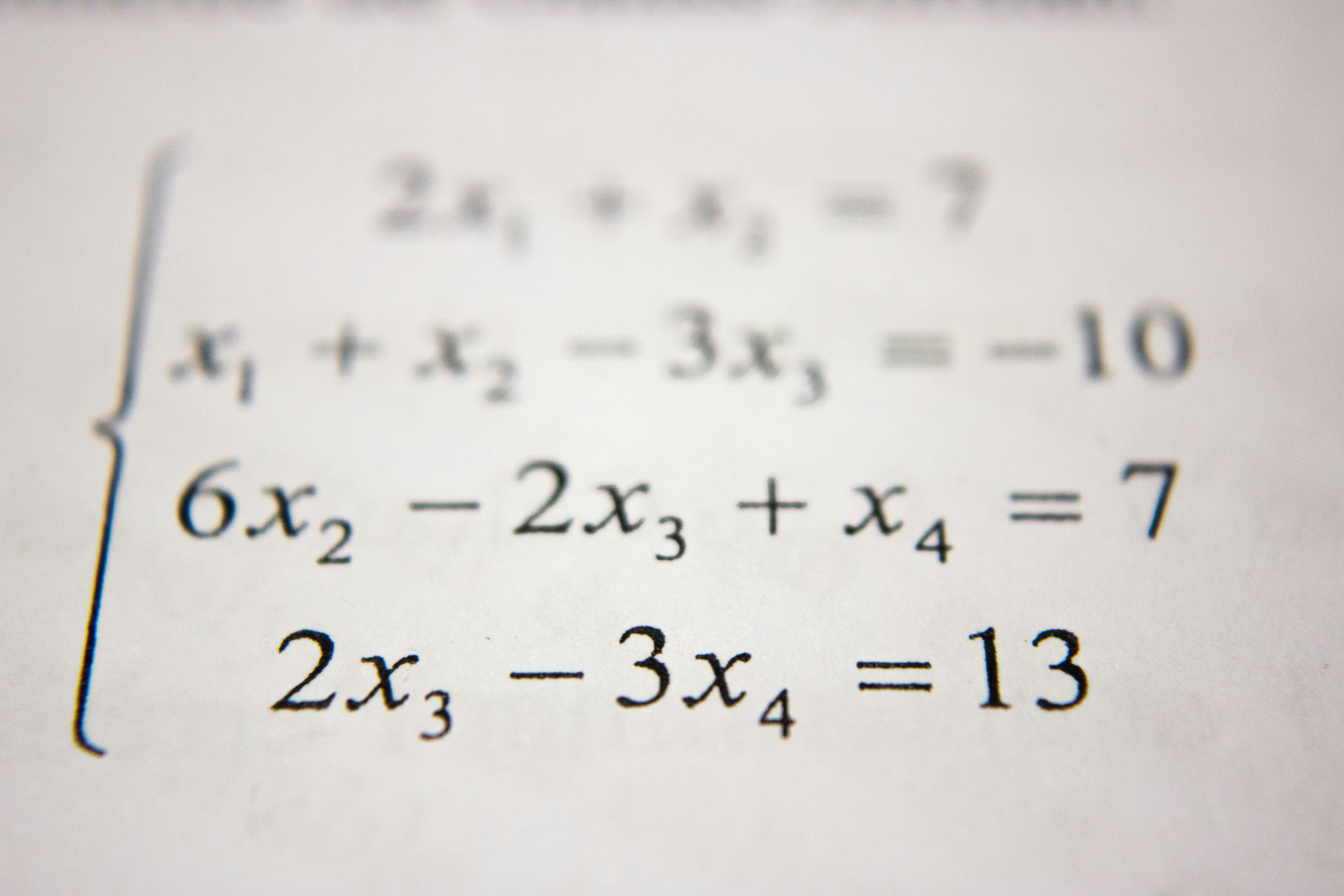
Descubre YAQA, el algoritmo de redondeo adaptativo que reduce el error de cuantización un 30% sin sobrecarga. Preserva la distribución del modelo original.

Descubre cómo PrimeSVT automatiza la poda de Transformers de Visión Spiking, reduciendo memoria un 26.68% con mínima pérdida de precisión. Optimiza tus modelos.

WaterSIC: algoritmo de cuantización casi óptimo que supera a GPTQ. Nuevo récord en LLMs Llama y Qwen para 1-4 bits. ¡Mejora la eficiencia!

Analizamos el aprendizaje de características en destilación de conocimiento y presentamos Confusion Distillation, una auto-destilación eficiente que supera a otros métodos en 1.2%.
Descubre cómo fusionar múltiples LoRAs en un solo adaptador de bajo rango con Compress-then-Merge, mejorando eficiencia y rendimiento sin perder estructura.

La cuantización no destruye todas las características interpretables: un análisis revela que el 62% persiste en INT6, pero las métricas engañan.

Aprende cómo PSViT comprime SViT con poda estructural: 22% menos memoria y alta precisión.